How Lytica became a unique analytics company: Part 5
When I think about supply chain priorities, I see three interlocked circles of cost, security of supply, and compliance. These are three equal priorities, whose ranking changes depending upon the needs of the customer. In times of war, security of supply tops the list because without munitions you’re dead. With medical customers, its most often compliance. In the consumer market, it’s cost. When I talk with customers, they admit to having concerns with all three priorities.
In formulating the R&D program of our Advanced Technology Centre (ATC) for 2017 and 2018, our team proposed solutions that addressed these priorities, and they evaluated the solutions for impact on the customer experience. We used a model that linked the customer level, to the technology level, through a product level.
At the customer level, there is a desire to have Freebenchmarking.com (FBDC) reports delivered more quickly and to achieve higher match rates. We define this as match rates of 100% and reports within hours. We also see a need for better risk management information to determine where the greatest exposure exists to a supplier’s or manufacturer’s supply interruptions, or even bankruptcy. Access to reliable, manufacturer traceable, information on compliance is another need that appears to be inadequately supported. These needs can be satisfied with Lytica product level offerings either through enhancements to existing products or with new product releases or service offerings.
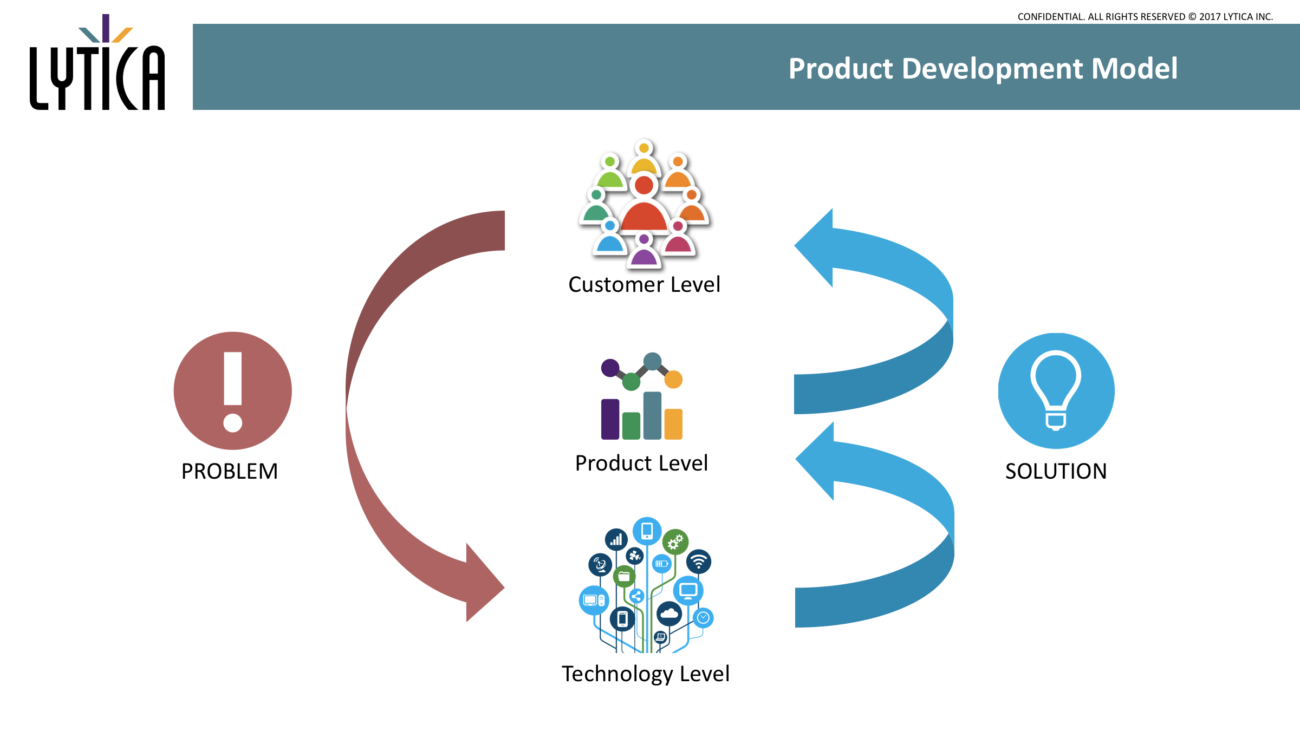
It’s at the technology level where things get interesting for the ATC. Data quality is at the heart of the FBDC report delivery interval problem and a contributing factor in the match rate one. Some customers are well aware of deficiencies in their data quality as a contributing factor to their daily challenges, while others recognize it as an issue but are unaware of the severity of its impact.
The data quality problem has a few common issues. One I refer to as spelling errors where characters have been changed, added or subtracted from the Manufacturer Part Number (MPN), sometimes burying the MPN in a soup of prefixes or suffixes. Another problem is keeping up with the sheer amount of data from manufacturers on product changes, lifecycles, mergers and acquisitions, compliance, and new regulatory standards. These are two examples where the ATC program can address the fundamental issues and provide new solutions to customers.
Consistency in MPN spelling is an interesting problem. We use spell check every day; in fact, as I write this blog it is in overdrive pointing out my typing errors. For spell-checking to work, one needs a comprehensive library against which words can be compared, as well as rules to determine how far a real word is from what was typed. The “how far off” part is usually determined by using Levenshtein distance and other AI techniques to see if the word fits the sentence. According to Michael Gilleland of Merriam Park Software, “Levenshtein distance is a measure of the similarity between two strings, which we will refer to as the source string (s) and the target string (t). The distance is the number of deletions, insertions, or substitutions required to transform s into t.” In spell check, the misspelled word and the reference one are “s” and “t”. Using Levenshtein distance, the number of characters that need to be changed to transform from the typed word to a reference word are counted (distance) and the reference words with the fewest required changes and the longest uninterrupted string of characters before and after a change has the best chance of being the correctly spelled word. Usually, with spell check the user is given a couple of options. In our application the approach is similar, but we use algorithms other than Levantine and, because MPN spell check runs in an automated system, we need ways to ensure that the correct MPN is chosen without human intervention or choice. We can do this by putting the MPN being spell-checked into context using other information about the MPN word. This spell check capability has great potential in data cleanup.
Keeping up with the sheer amount of data is another problem ideally suited to AI. A few weeks ago, CBS 60 Minutes aired a spot on AI that revealed performance that makes the supply chain “keeping up” problem seem trivial. Using IBM® Watson Technology, doctors gave the AI system 1 week of training (structured learning) on reading images from cancer patients. They then had it assess 1,000 images to diagnose cancers. Teams of doctors and radiologists had already studied these 1,000 images. The result, IBM’s Watson identified all of the cancers the doctors had found. The surprise, the machine identified 30% more than the doctors found which were subsequently confirmed by doctors. The astounding bit, there are 8000 medical papers on cancer published per day. No doctor can keep up. IBM’s Watson reads every new paper each day, synthesises it and uses this new knowledge to improve its diagnosis. The ATC’s AI system will do the same thing to keep information on manufactures current.
Once we have the technology in place, we can productize it and solve chronic customer problems. Our first ATC milestones pertain to match rates and MPN spell checking. These are followed by activities to resolve data clean up issues in addition to spelling such as Mergers and Acquisitions (M&A) name change management, as well as creating new risk metrics reports and compliance mechanisms. Let me know where your priorities lie, so I can tune the projects for maximum impact for your business!
Follow this blog series on SCM Roundtable to learn more about the ATC and our plans for its evolution.
Ken Bradley is the Chairman/CTO & founder of Lytica Inc., a provider of supply chain analytics tools and Silecta Inc., a SCM Operations consultancy.